端到端实验chr19的微缩版

End-to-end target discovery with GWAS and PheWAS(19号染色体微缩版)
1.实验介绍
本实验源于End-to-end target discovery with GWAS and PheWAS | Research Analysis Platform的端对端的基因组靶点发现,以缺血性心脏病作为表型示例。分析的第一步时建立病例组和对照组。之后对于队列的样本数据进行筛选。之后对于基因组数据,芯片数据和插补数据及逆行清洗处理。接着展开局部部分的GWAS分析,并采用连锁不平衡聚类方法整合出显著的关联变异位点。最后针对每个变异位点进行表型关联分析(PheWAS)
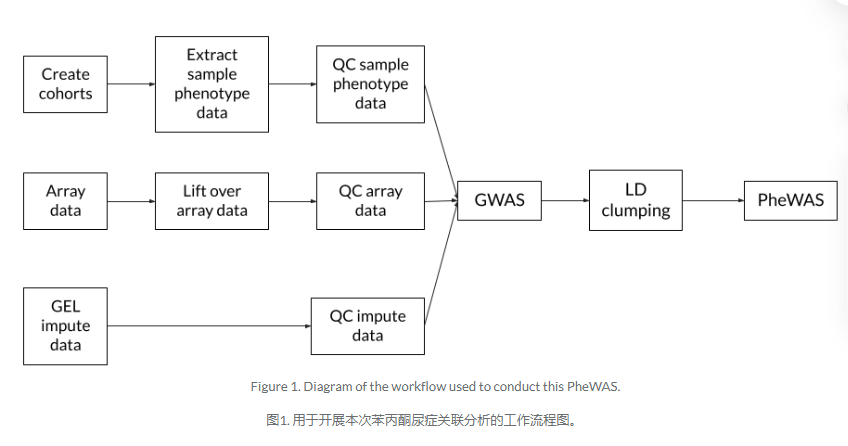
数据
基因组数据
采用了两种基因组数据:芯片数据(array data)和插补数据(imputed data)。在处理连锁不平衡现象时仅用了插补数据.
表型数据
首先选择缺血性心脏病作为目标表型(ICD-10编码I20-I25),同时为样本质量控制检索了以下字段:
- 31 - Sex
- 22001 - Genetic sex 22001 - 遗传性别
- 22006 - Genetic ethnic grouping22006 - 基因族裔分组
- 22019 - Sex chromosome aneuploidy22019 - 性染色体非整倍体
- 22020 - Used in genetic principal components22020 - 用于遗传主成分分析
为提高统计效能,并减少假阳性可能,GWAS和PheWAS使用了以下的协变量
- 31 - Sex
- 2966 - Age high blood pressure diagnosed (not used in PheWAS)2966 - 高血压确诊年龄(未用于PheWAS)
- 21022 - Age at recruitment21022 - 招募时的年龄
- 23104 - Body mass index (BMI)23104 - 身体质量指数(BMI)
- 20160 - Ever smoked 20160 - 曾经吸过烟
- 30760 - HDL cholesterol (not used in PheWAS)30760 - 高密度脂蛋白胆固醇(未用于苯丙酮尿症基因组关联研究)
- 30780 - LDL direct (not used in PheWAS)30780 - LDL直接检测(未用于苯丙酮尿症关联分析)
- 22009 - Genetic principal components22009 - 遗传主成分分析
2.创建队列
创建好队列,就可以用于后续分析(GWAS),本分析所采用的表型比较简单,但实际上可能包含多个字段。
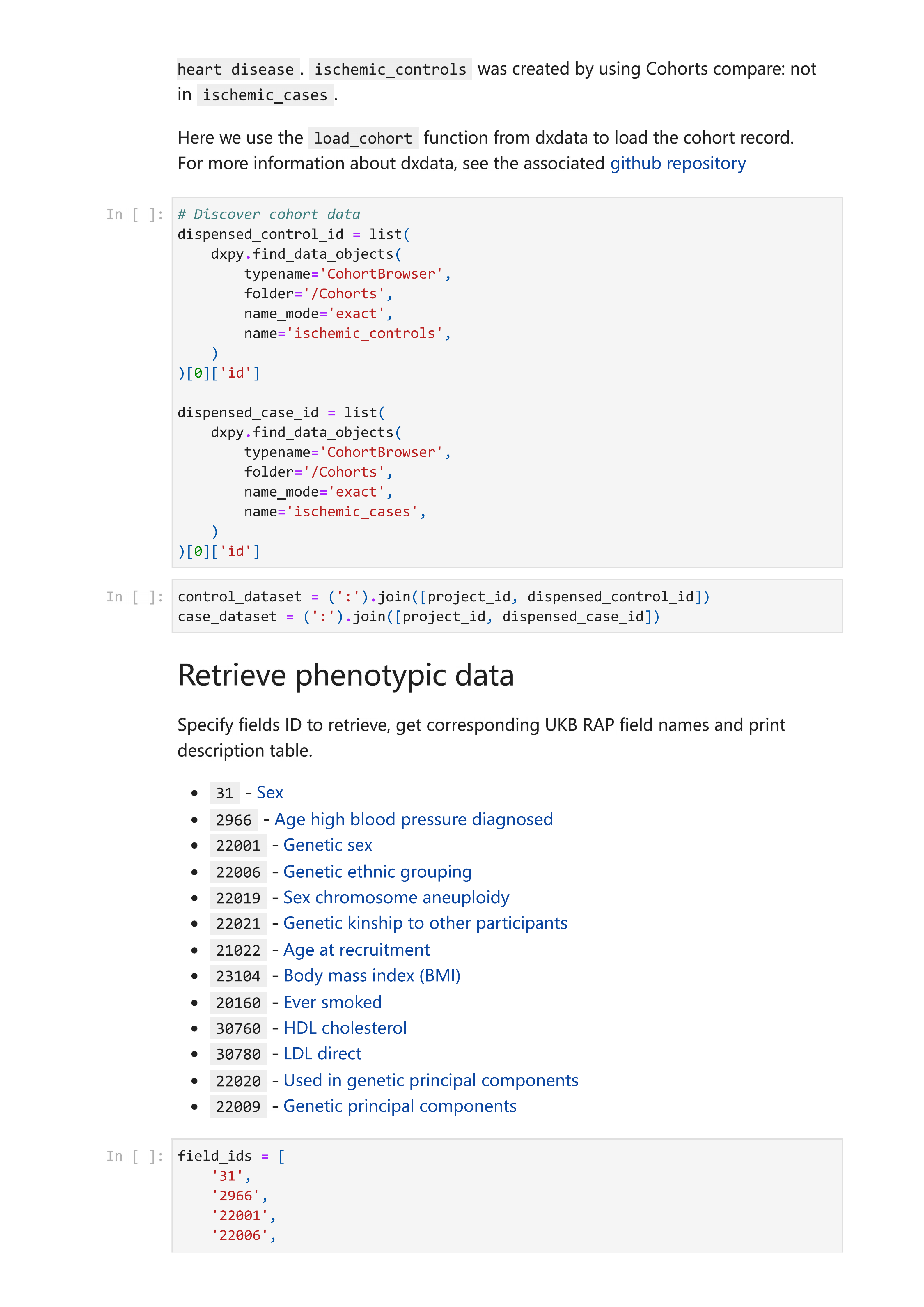
首先,使用队列浏览器创建选定的队列。通过在字段41270中选择具有I20-I25缺血性心脏病的参与者,创建了”ischemic_cases”队列。 “ischemic_controls”队列通过在”ischemic_cases”中使用”队列比较:非”选项创建。最终形成包含57,383例”ischemic_cases”和445,027例”ischemic_controls”的样本。
UI界面
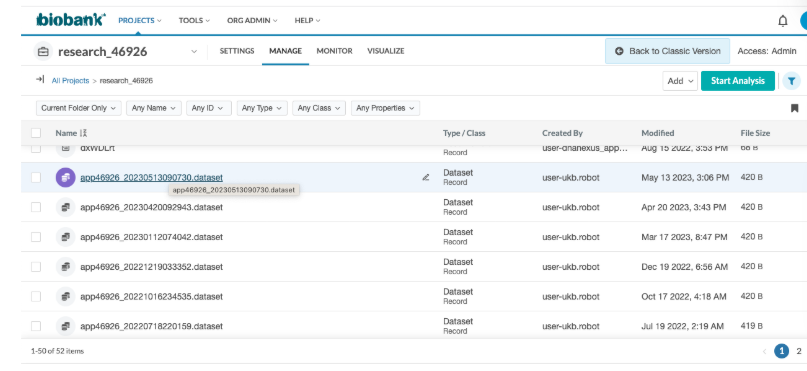
1.在RAP中,请点击”管理”选项卡下的目标数据集。如下方图片所示,点击数据集名称即可进入队列浏览器页面。
2.然后,点击“添加筛选器”按钮。在搜索栏中输入“缺血性心脏病”(ischaemic heart disease),并选择“诊断 - ICD10”(数据字段为41270)。点击“添加队列筛选器”确认选择。
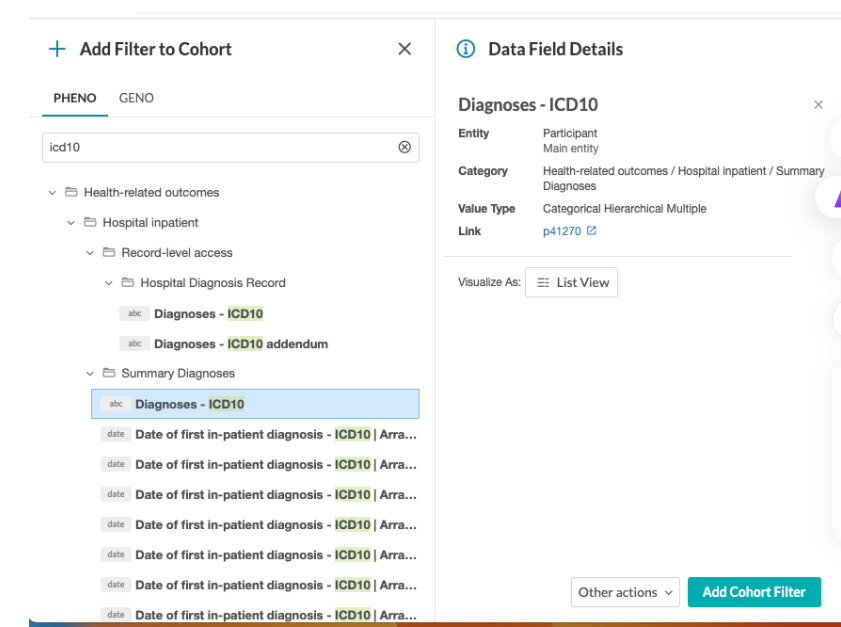
3.在“包含以下任何一项”Includes any of的模态提示框中,输入“I20-I25 缺血性心脏病”(I20-I25 Ischaemic heart disease)并选择该选项。然后点击“应用筛选器”(Apply Filter )按钮
4.命名队列。在此示例中,队列名为“ischemic_cases”(注:示例队列名称采用美式拼写,但提及特定UKB数据字段时将使用英式拼写)
创建对照组
1.要创建对照组,请点击“+”按钮(鼠标悬停提示:“比较/合并队列”(Compare/combine cohort))。

2.从下拉菜单中选择“不在缺血病例中”选项,并应用此筛选条件。
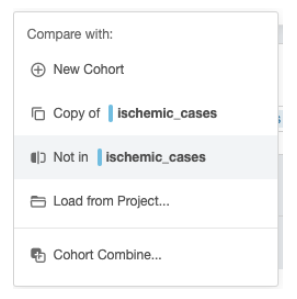
3.命名并保存该队列。在此示例中,”ischemic_cases”队列包含57,383个样本,而”ischemic_controls”队列包含445,027个样本。(病例组和对照组都需要进行保存,以便在对应的个体质量控制进行)
样本质量控制
样本清理可降低数据噪声,提高全基因组关联分析结果的准确性。例如,通过检查性别不一致和性染色体非整倍体,可排除可能的样本混淆和基因分型错误。通过仅选择单一人群(白人英国人),最大限度地减少了群体亚结构的影响。为验证表型与基因型的关联性,在选择用于计算主成分分析的样本时,仅选取了非亲属参与者的样本。
概述
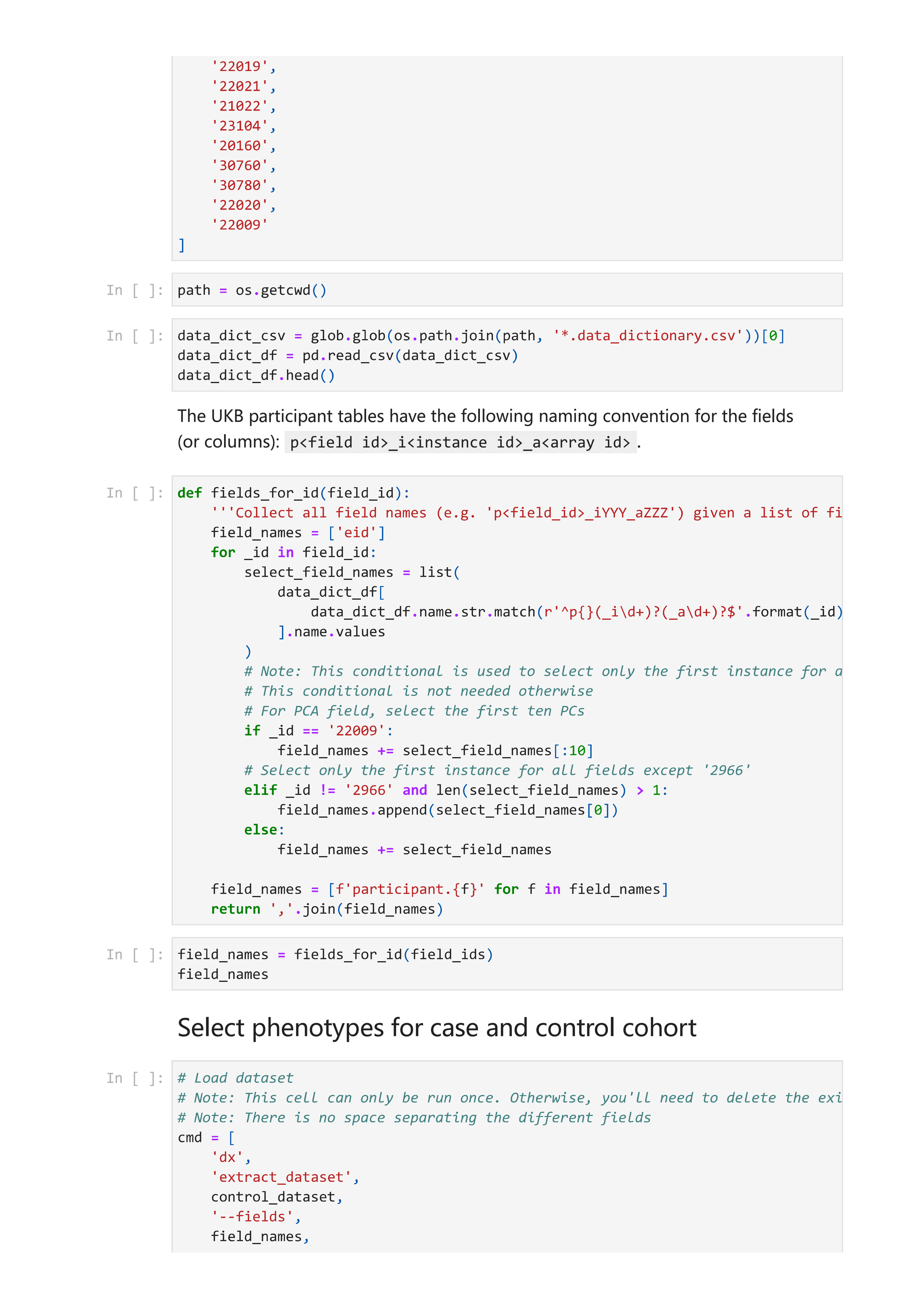
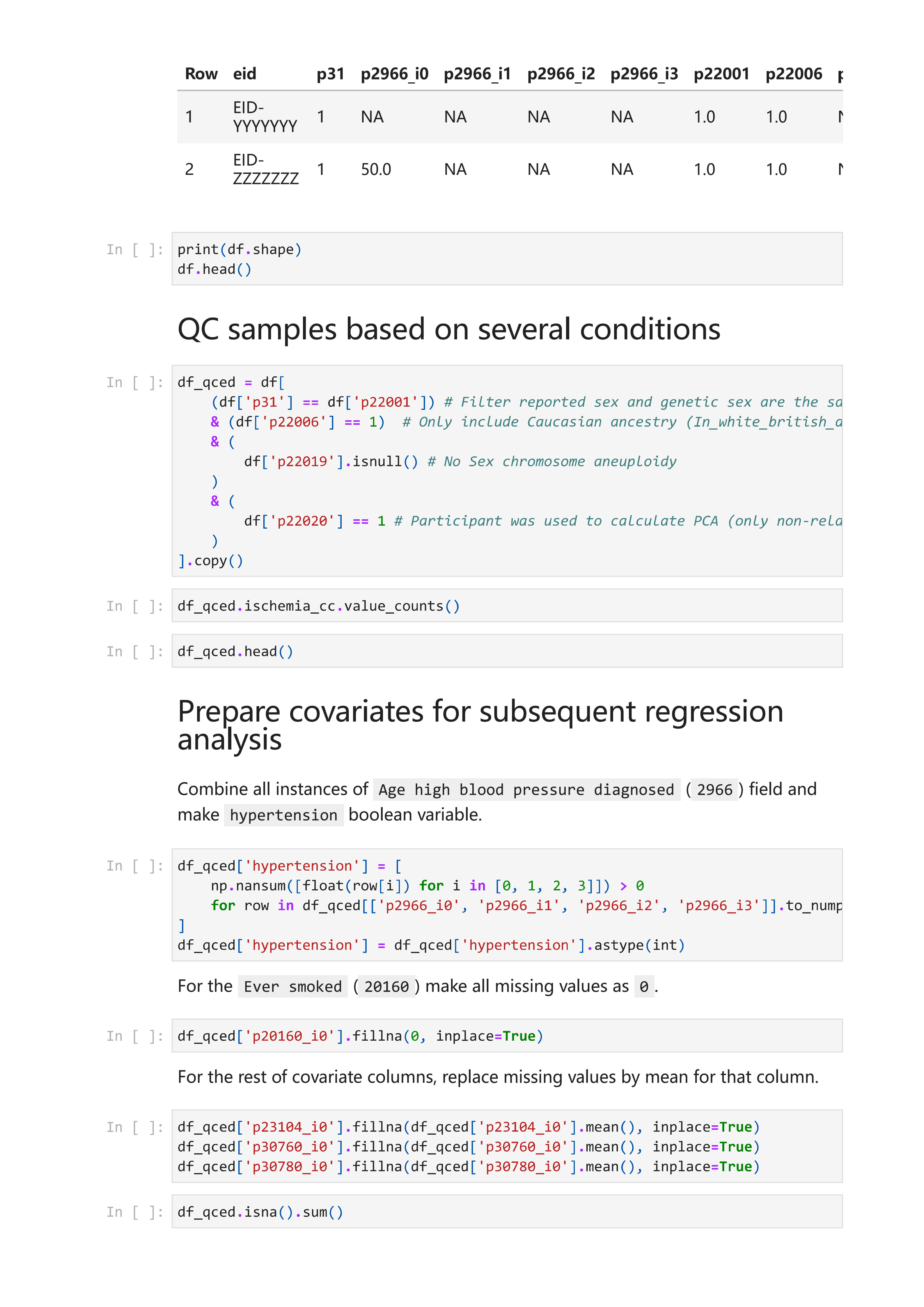
样本质量控制的代码可在gwas-phenotype-samples-qc.ipynb中找到。使用dx extract_dataset将每个队列的表型数据提取为表格。随后,根据以下标准筛选样本
-
Sex and genetic sex are the same性别与遗传性别相同
- Participant has White British ancestry参与者具有白人英国血统
- Not sex chromosome aneuploidy 非性染色体非整倍体
- Participant was used to calculate PCA (only non-relatives were included)使用参与者数据计算PCA(仅包含非亲属个体)
过滤后,”缺血病例”组和”缺血对照”组分别保留了38,197个和298,886个样本。
表型插值示例
质量控制后,协变量作为全基因组关联分析流程的一部分进行了插补。协变量及上述笔记本代码对数据进行清理的操作摘要如下:
-
Age high blood pressure diagnosed in participant (2966) field 参与者(2966)高血压确诊年龄字段
- The code combines all instances and create the hypertension boolean variable该代码将所有实例合并,并创建高血压布尔变量。
- Participant ever smoked 参与者是否曾吸烟
- The code makes all missing values as 0该代码将所有缺失值设为0。
- Participant body mass index (BMI), HDL cholesterol, direct LDL参与者体重指数(BMI)、高密度脂蛋白胆固醇、直接低密度脂蛋白
- The code replaces missing values by mean for that variable该代码用该变量的均值替换缺失值。
table contained 38,197 cases and 298,886 controls. 随后,表型数据与可获得插补数据的样本列表进行了合并。最终生成的表格包含38,197例病例和298,886例对照。
样本质量控制代码